

微服务
认识微服务
微服务是一种软件设计模式,它将应用程序拆分成小型、相互独立的服务,每个服务都可以通过标准化的接口进行通信和交互。
这些服务通常部署在容器中,每个服务都可以独立地进行扩展、升级和维护,从而提高了系统的灵活性、可伸缩性和可靠性。
与传统的单体式架构不同,微服务的架构可以更轻松地适应快速变化的业务需求,并且可以更容易地实现持续集成和持续部署(CI/CD)的流程。
微服务的特点:
- 单一职责:微服务拆分颗粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,避免重复业务开发
- 面向服务:微服务对外暴露业务接口
- 自治:团队独立、技术独立、数据独立、部署独立
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题】
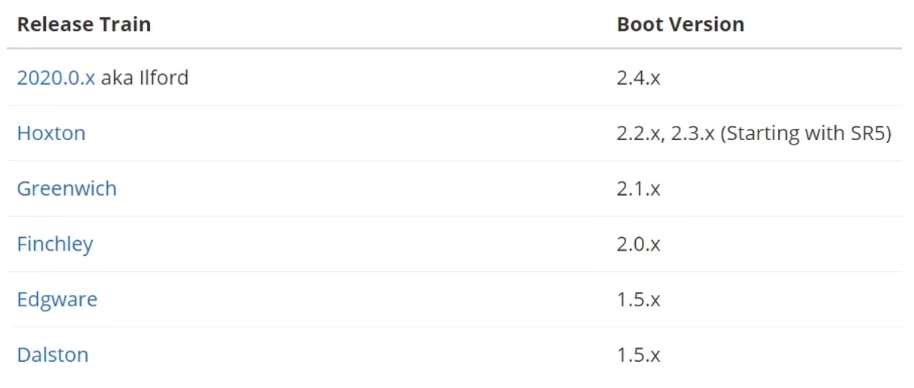
SpringCloud与SpringBoot的版本兼容关系
远程调用
微服务的远程连接实例通常采用 RESTful API 或 RPC(Remote Procedure Call)来实现。
RESTful API 是一种基于 HTTP 协议的轻量级的、可扩展的架构风格,它使用明确的 URL 和 HTTP 方法(例如 GET、POST、PUT、DELETE)来表示对资源的操作。每个微服务都提供一组 RESTful API,其他微服务可以通过调用这些 API 来访问和使用该服务提供的功能。
使用步骤:
注册RestTemplate
在order-service的OrderApplication中注册RestTemplate
1
2
3
4
5
6
7
8
9
10
11
12
13
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
public RestTemplate restTemplate(){
return new RestTemplate();
}
}服务远程调用RestTemplate
修改order-service中的OrderService的queryOrderById方法
也就是通过http连接获取到user获取到的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class OrderService {
private OrderMapper orderMapper;
private RestTemplate restTemplate;
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.利用RestTemplate发送http请求,查询用户
// 2.1设置url路径
String url="http://localhost:8081/user/"+order.getUserId();
// 2.2发送http请求,远程调用
User user = restTemplate.getForObject(url, User.class);
// 3.封装user到order
order.setUser(user);
// 4.返回
return order;
}
}
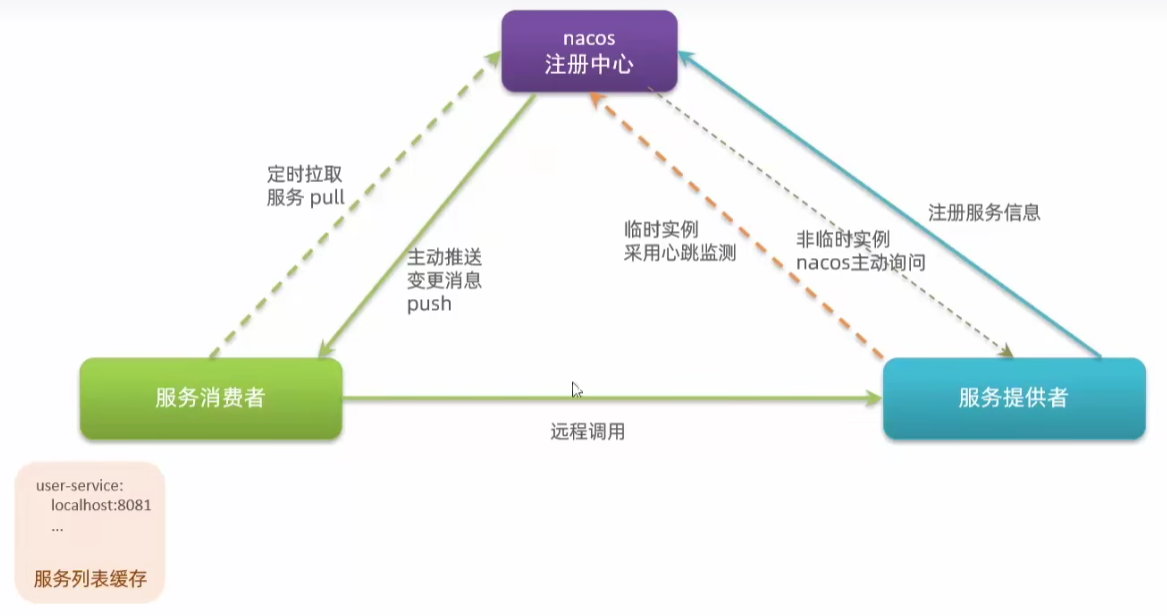
Eureka注册中心
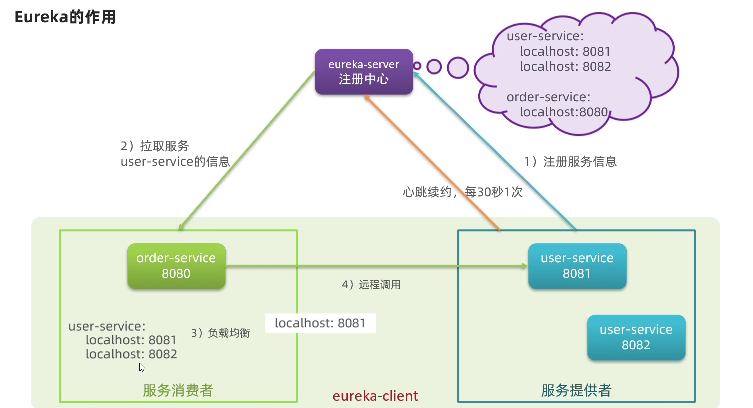
在一个大型的分布式系统中,服务往往会有多个实例运行在不同的机器上,而这些服务之间又需要相互通信,这时就需要一个中心化的服务注册和发现机制,来管理服务的实例和状态。
Eureka概念
通过 Eureka,我们可以很方便地将一个服务注册到 Eureka 服务器,并让其他服务消费该服务
服务提供者和服务消费者统称为eureka客户端
Eureka注册中心执行步骤:
在服务提供者启动时会自动将注册服务信息发送给eureka
eureka接收到注册信息例如:
user-service:
localhost:8081
localhost:8082
localhost:8083
order-service:
localhost:8080
消费者使用时会找rureka拿取注册信息
例如想要请求user-service的信息,eureka就会将注册信息通过负载均衡向服务提供者发送请求
注:服务消费者不会拿到死掉的地址,因为服务提供者会每隔30s发送一次心跳确认状态
搭建eureka服务
创建项目,引入spring-cloud-starter-netflix-eureka-server
1
2
3
4
5<dependency>
<groupId>org.springframework.cloud</groupId>
artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
<version>2.2.7.RELEASE</version>
</dependency>注意:springboot、springcloud和eureka版本要对应
编写启动类,添加@EnableEurekaServer注解
1
2
3
4
5
6
7
8
9
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}添加application.yml文件,编写下面的配置
1
2
3
4
5
6
7
8
9server:
port: 10086 #服务端口
spring:
application:
name: eurekaserver #eureka的服务名称
eureka:
client:
service-url: #eureka的地址信息
defaultZone: http://127.0.0.1:10086/eureka文件结构:eureka以子文件形式出现
服务注册
服务注册,就是将提供某个服务的模块信息(通常是这个服务的ip和端口)注册到1个公共的组件上去
在order-service项目引入spring-cloud-starter-netflix-eureka-client的依赖
1
2
3
4
5<dependency>
<groupId>org.springframework.cloud</groupId>
artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
<version>2.2.7.RELEASE</version>
</dependency>在application.yml文件,编写下面的配置
1
2
3
4
5
6
7
8
9server:
port: 8080 #服务端口
spring:
application:
name: eurekaserver #eureka的服务名称
eureka:
client:
service-url: #eureka的地址信息
defaultZone: http://127.0.0.1:10086/eureka
服务发现
服务发现,就是新注册的这个服务模块能够及时的被其他调用者发现。不管是服务新增和服务删减都能实现自动发现。
修改OrderService的代码,修改访问的url路径,用服务名代替ip、端口:
1
String url="http://userservice/user/"+order.getUserId();
在order-service项目的启动类OrderApplication中的RestTemplate添加负载均衡注解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
//实现负载均衡
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
Ribbon负载均衡
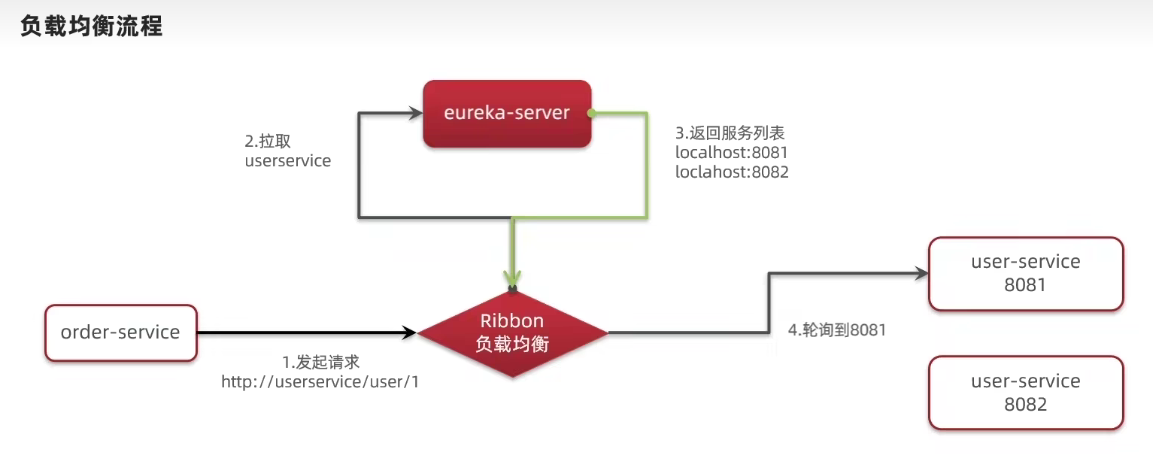
通过IRule实现可以修改负载均衡规则,有两种方式:
添加依赖:您需要将Spring Cloud Ribbon依赖添加到您的项目中。 您可以在pom.xml文件中添加以下代码:
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>代码方式:在order-service中的OrderApplication类中,定义一个新的IRule:
1
2
3
4
5
public IRule randomRule({
//实行随机分配负载
return new RandomRule();
}配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则
1
2
3
4userservice:
ribbon:
#负载均衡规则
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
懒加载和饥饿加载
懒加载:在第一次发起请求的时候才会创建LoadBalancerClient对象,就会导致第一次访问时长比较久
饥饿加载:饥饿加载是指在启动项目时就创建LoadBalancerClient对象,并在后续请求中只使用一个LoadBalanceClient对象,从而减少了一开始就请求大量资源所带来的延迟和耗电量。
程序默认为懒加载:
1 | ribbon: |
Nacos
下载安装运行
下载1.4.1版本
Release 1.4.1 (Jan 15, 2021) · alibaba/nacos · GitHub

解压安装
运行bin/startup.cmd
使用necos注册中心
在父组件的pom文件中
1
2
3
4
5
6
7
8<!--nacos组件-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>在子组件中去掉eureka依赖,并加上
1
2
3
4<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>配置yaml文件,去掉eureka的并添加:
1
2
3
4spring:
cloud:
nacos:
server-addr: localhost:8848
注:在运行程序时,记得启动nacos
Nacos服务分级存储模型
在企业中,一般我们会把服务的多个实例分放在多个机房以达到容灾
服务调用尽可能选择本地集群的服务,跨集群调用延迟较高
本地集群不可访问时,再去访问其它集群
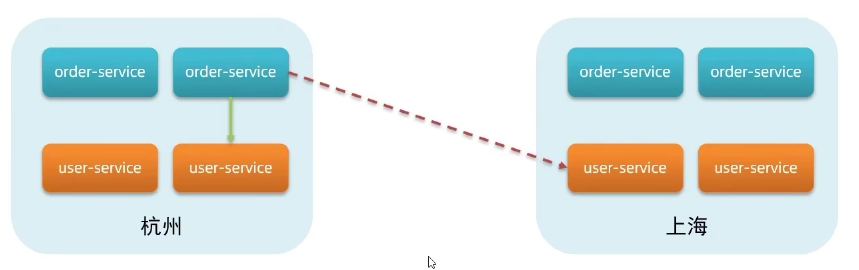
Nacos服务分级存储模型
- 一级是服务,例如userservice
- 二级是集群,例如杭州或上海
- 三级是实例,例如杭州机房的某台部署了userservice的服务器
服务集群属性设置:
修改application.yml,添加如下内容
1
2
3
4
5
6spring:
cloud :
nacos:
server-addr: localhost:8848 # nacos服务端地址
discovery:
cluster-name: HZ #配置集群名称,也就是机房位置,例如:HZ,杭州
加权负载均衡
Nacos控制台可以设置实例的权重值,0~1之间同集群内的多个实例,
权重越高被访问的频率越高权重
设置为0则完全不会被访问
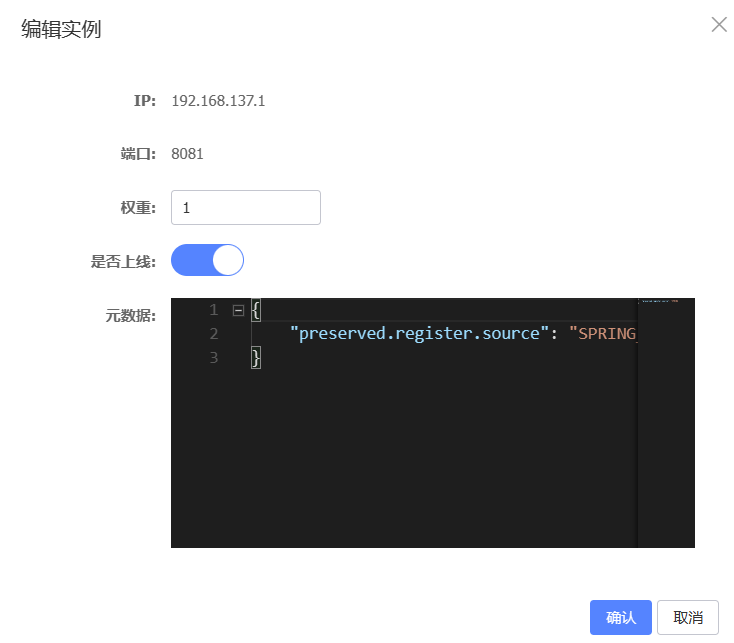
环境隔离
Nacos中服务存储和数据存储的最外层都是一个名为namespace的东西,用来做最外层隔离
Nacos环境隔离
namespace用来做环境隔离
每个namespace都有唯一的id
不同namespace下的服务不可见
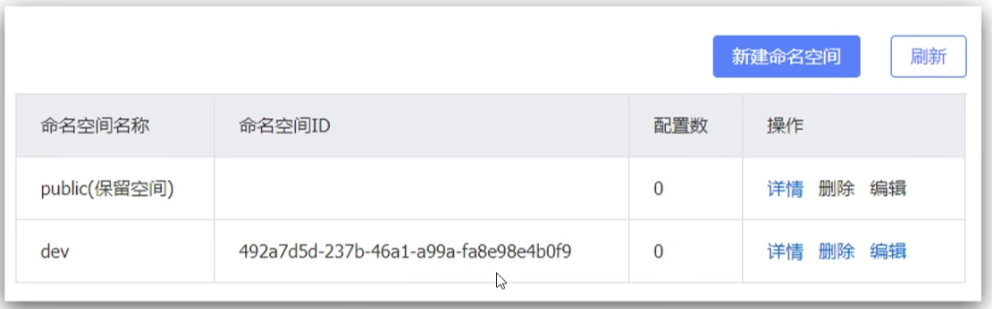
在Nacos控制台可以创建namespace,用来隔离不同环境
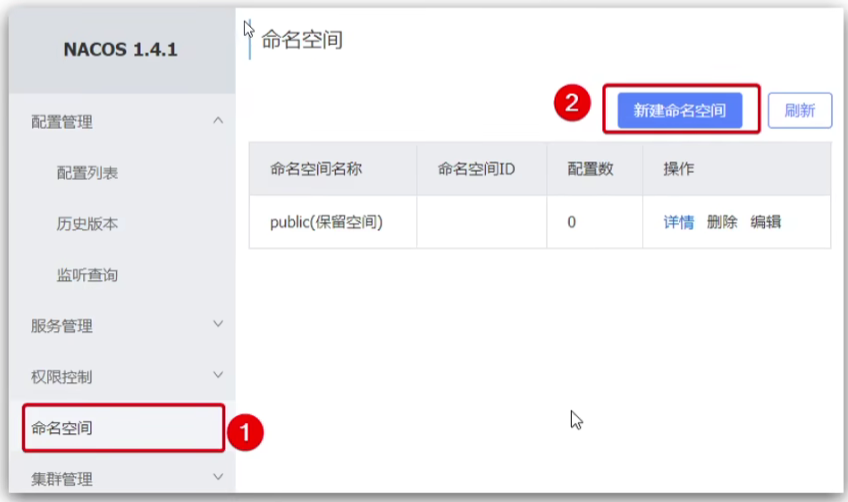
设置新命名空间
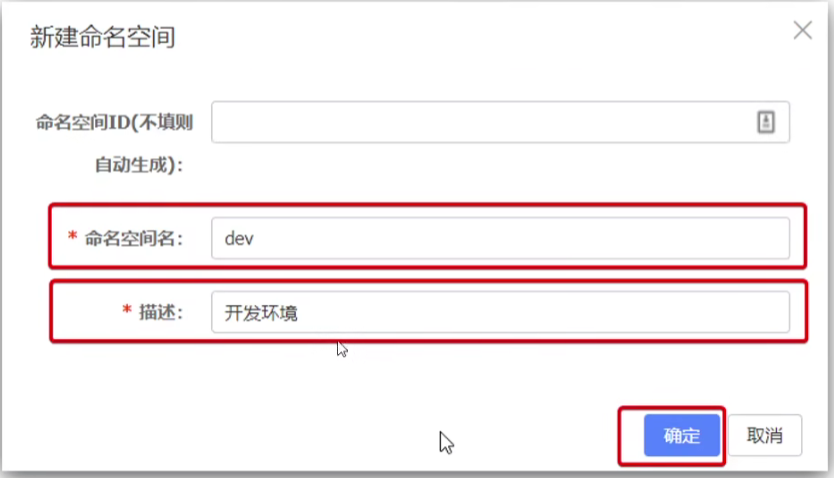
保存后会在控制台看到一个命名空间id
修改order-service的application.yml,添加namespace:
1
2
3
4
5
6
7spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: SH #上海
namespace: 492a7d5d-237b-46a1-a99a-fa8e98e4b0f9 #命名空间,填ID
临时实例和非临时实例
临时实例和非临时实例区别:
临时实例:每隔三十秒向注册中心发送心跳
非临时实例:不自动发送心跳,由注册中心询问,更新速度更快
服务注册到Nacos时,可以选择注册为临时或非临时实例,通过配置的配置来设置
1 | spring: |
Nacos与Eureka的区别
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
Nacos统一配置管理
Nacos不只是有强大的注册中心功能,他同时还兼备配置管理功能。所谓统一配置就是将这一个微服务中都能用到的配置放在一个文件中,并且能实现热更新
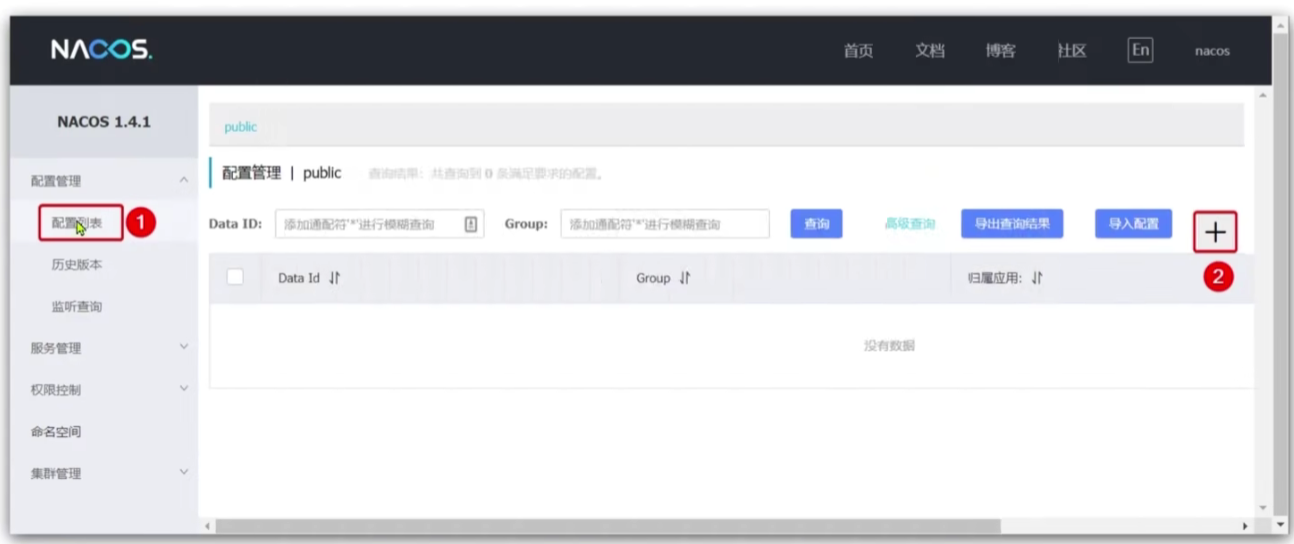
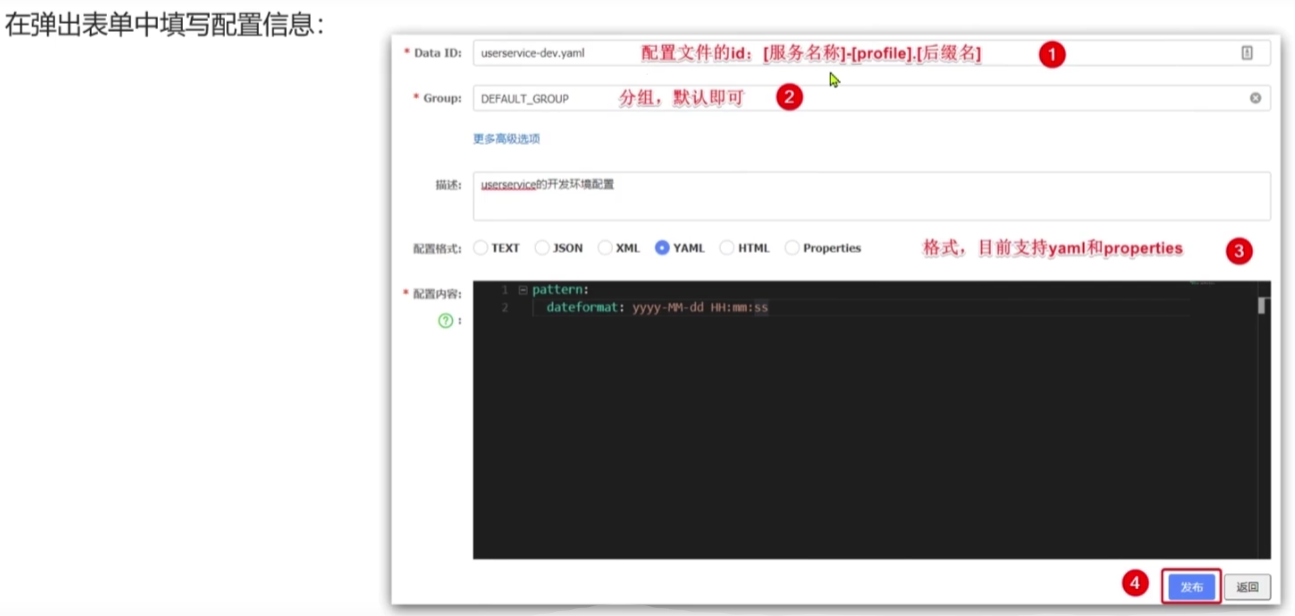
服务获取配置
配置获取的步骤如下:
项目启动时会优先读取一个叫bootstarp.yml的文件,然后再将这个文件和本地的application.yml相结合,在通过这俩配置文件的结合体来创建spring容器最后加载bean
具体步骤:
引入Nacos的配置管理客户端依赖
1
2
3
4
5<! --nacos配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>在userservice中的resource目录添加一个bootstarp.yaml文件,这个文件是引导文件,优先级高于application.yaml:
1
2
3
4
5
6
7
8
9
10spring:
application:
name: userservice #服务名称,和nacos注册中心名称一致
profiles:
active: dev #开发环境,这里是dev
cloud:
nacos:
server-addr: localhost:8848 #Nacos地址
config:
file-extension: yaml#文件后缀名可以在user-servie中将pattern.dateformat这个属性注入到UserController中做测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class UserController {
//注入nacos中的配置属性
private String dateformat;
//编写controller,通过日期格式化器来格式化当前时间并返回
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));
}
}另外,Nacos配置更改后,微服务可以实现热更新,有两种方法:
- 通过@value注解注入,结合@RefreshScope来刷新
- 通过@ConfigurationProperties注入,自动刷新
优先级:
服务名-环境.yaml>服务名.yaml>本地配置
Nacos集群搭建步骤
搭建MySQL集群并初始化数据库表
下载解压nacos
修改集群配置(节点信息)、数据库配置
进入nacos的conf目录,修改配置文件cluster.conf.example重命名为cluster.conf
添加内容,集群中每一个节点的信息
127.0.0.1:8845
127.0.0.1:8846
127.0.0.1:8847
修改application.properties文件,添加数据库配置
1
2
3
4
5
6
7
8#数据源,告诉nacos用的什么集群
spring.datasource.platform=mysq1
#有几台机器
db.num=1
db.ur1.O=jdbc:mysq7://127.0.0.1:3306/nacos?
characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useunicode=true&usessL=fa1se&serverTimezone=UTC
db.user.0=root I
db.password.0=123
分别启动多个nacos节点
nginx反向代理
修改conf/nginx.conf文件,配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14//放置集群地址,方便nginx设置反向代理
upstream nacos-cluster {
server 127.0.0.1:8845;
server 127.0.0.1:8846;
server 127.0.0.1:8847;
}
server {
listen 80;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}
Feign
基于Feign的远程调用
步骤:
引入依赖
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>创建UserClient
1
2
3
4
5
public interface UserClient {
User findById( Long id);
}在springboot启动类中添加注解
1
@EnableFeignClients
修改之前的orderService.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class OrderService {
private OrderMapper orderMapper;
private UserClient userClient;
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.用Feign远程调用
User user = userClient.findById(order.getUserId());
// 3.封装user到order
order.setUser(user);
// 4.返回
return order;
}
}
Feign的性能优化
在Fegin的默认中是不支持连接池的URLConnection,因此每次请求都会进行三次握手和四次挥手大大提高了响应速度,因此我们对Fegin的性能优化首先就要解决让Fegin支持连接池
Fegin中底层的客户端实现:
URLcontroller:默认实现,不支持连接池
Apache HttpClient:支持连接池
OKHttp:支持连接池
这里主要介绍使用Apache HttpClient的使用方法
引入依赖
1
2
3
4<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>配置连接池
1
2
3
4
5
6
7
8
9feign:
client:
config:
default: #default全局的配置
loggeiLevel: BASIC #日志级别,BASIC就是基本的请求和晌应信息
httpclient:
enabled : true #开启feign对HttpClient的支持
max-connections: 200 #最大的连接数
max-connections-per-route: 50 #每个路径的最大连接数
Feign最佳实践
- 将clients和pojo的user单独分离出来成为fegin-api
- 将fegin-api当做包引用
- 可能会遇到的问题:自动注入不成功
解决方法:
在@EnableFeignClients注释中添加basePackages,指定FeignClient所在的包
1
在@EnableFeignClients注解中添加clients,指定具体Feignclient的字节码
1
EnableFeignclients(clients = {Userclient.class})
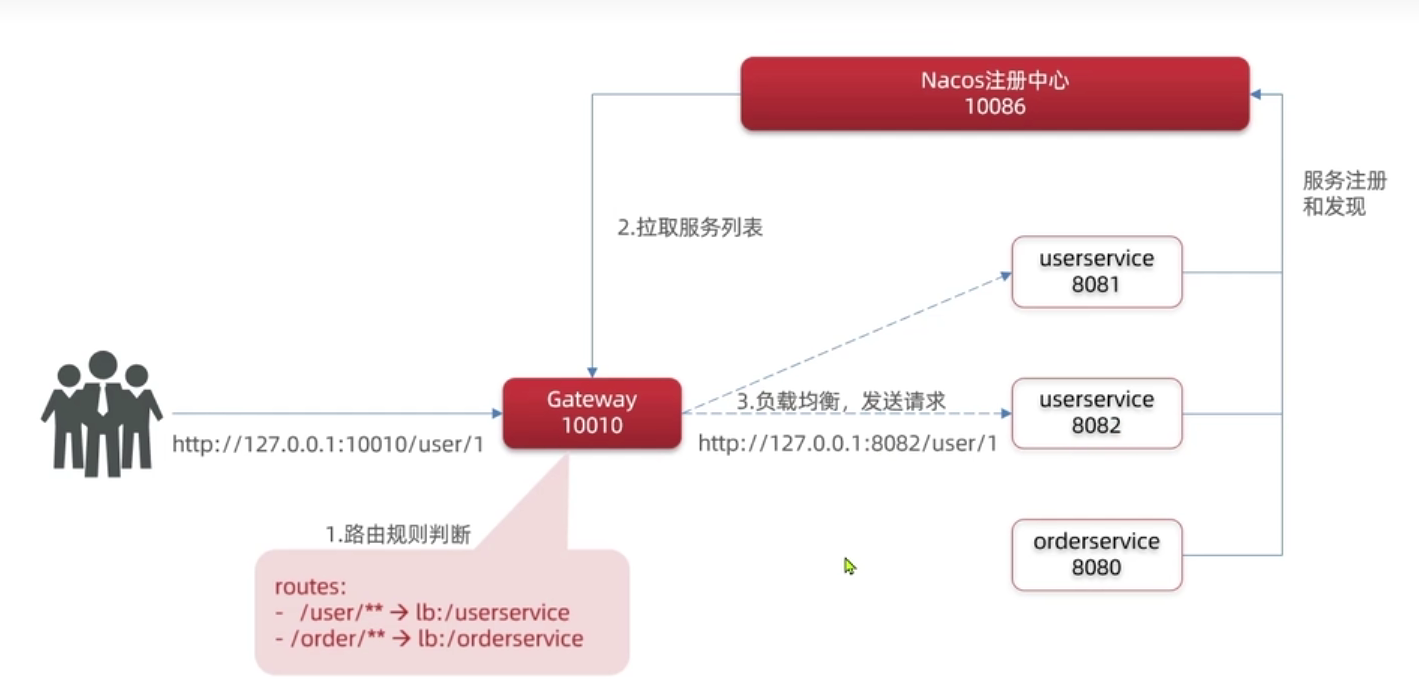
统一网关Gateway
为什么需要网关
网关的功能:
- 身份验证和权限检测
- 服务路由、负载均衡
- 请求限流
快速入门
搭建网关服务的步骤:
创建新的module,引入SpringCloudGetway的依赖和nacos的服务发现依赖
1
2
3
4
5
6
7
8
9<! --网关依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<! --nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency>编写路由配置及nacos地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19server:
port: 10010 #网关端口
spring:
application:
name: gateway #服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
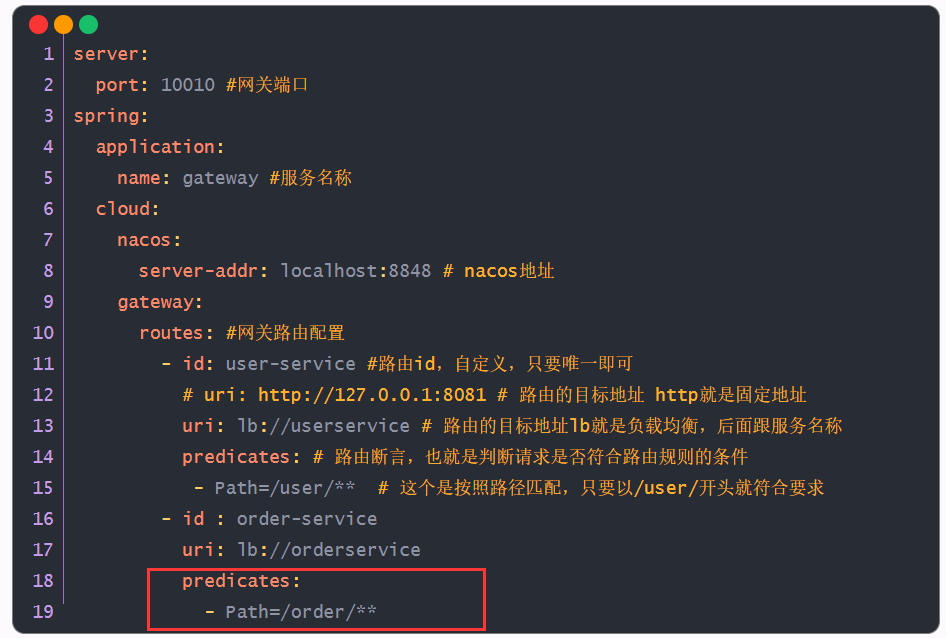
routes: #网关路由配置
- id: user-service #路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址
uri: lb://userservice # 路由的目标地址lb就是负载均衡,后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
- id : order-service
uri: lb://orderservice
predicates:
- Path=/order/**网关执行流程:
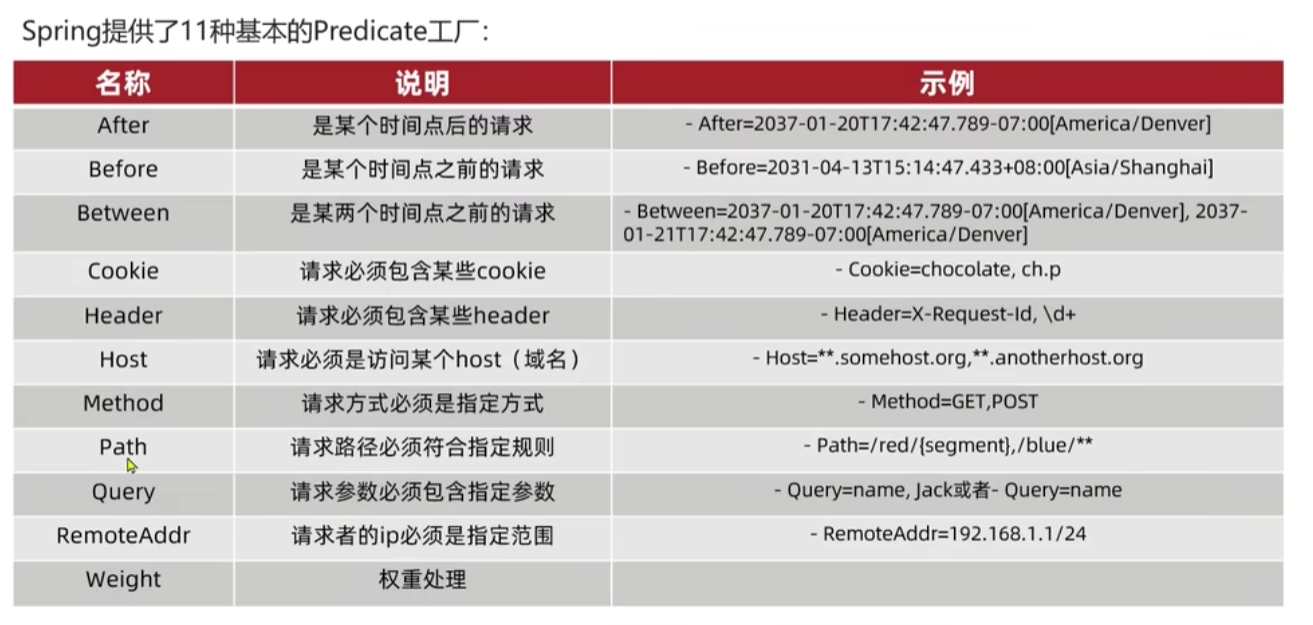
断言工厂
网关需要符合所有的断言工厂才能正常分配
过滤器工厂
过滤器的作用:
- 对路由的请求或响应做加工处理,比如添加请求头
- 配置在路由下的过滤器只对当前路由的请求生效
例如:给所有进入userservice的请求添加一个请求头: Truth=itcast is freaking awesome!
实现方式:
- 在gateway中修改application.yml文件,给userservice的路由添加过滤器:
1 | spring: |
在方法中接收
1
2
3
4
5
public User queryById( Long id ,
String truth) {
return userService.queryById(id);
}
默认过滤器
如果要对所有的路由都生效,则可以将过滤器工厂写到default下,格式如下:
1 | spring: |
全局过滤器
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。
区别在于GatewayFilter通过配置定义,处理逻辑是固定的。而GlobalFilter的逻辑需要自己写代码实现。定义方式是实现GlobalFilter接口。
1 | /*order设置优先级,数字越低优先级越高*/ |
跨域问题处理
跨域:域名不一致就是跨域,主要包括:
- 域名不同:www.taobao.com和www.taobao.org
- 域名相同,端口不同:localhost:8080和localhost:8081
跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
1 | spring: |
Docker分布式部署
项目部署的问题
大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题:
- 依赖关系复杂,容易出现兼容性问题
- 开发、测试、生产环境有差异
Docker如何解决依赖的兼容问题
首先我们要知道,linux系统分为很多种,例如:Ubuntu、centos等,他们都是基于linux内核,而linux内核通过固定的指令就能操作硬件。而每个系统的差异就是因为打包linux指令的函数式不同,函数式不同就会造成不同的系统无法执行同一个命令。
Docker如何解决:
Docker将用户程序与所需要调用的系统(例如centos)函数库一起打包成可移植的镜像
Docker运行到不同的操作系统时,直接基于打包的库函数,借助操作系统的linux内核来运行
安装、卸载Docker
centos安装Docker
1 | yum install -y yum-utils device-mapper-persistent-data lvm2 --skip-broken |
设置Docker下载源
1 | 设置docker镜像源 |
卸载Docker
1 | yum remove docker \ |
配置镜像加速
docker官方镜像仓库网速较差,我们需要设置国内镜像服务:
参考阿里云的镜像加速文档:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
docker获取镜像
Docker Hub Container Image Library | App Containerization
1 | docker pull nginx |
docker其他命令
1 | #启动 Docker 服务 |
docker容器命令
- docker run:创建并启动一个新容器。
例如,使用下面的命令可以启动一个基于nginx镜像的名为 mycontainer 的容器
1 | docker run --name mycontainer -p 80:80 -d nginx |
docker run :创建并运行一个容器
–name:给容器起一个名字,比如叫做mn
-p∶将宿主机端口与容器端口映射,冒号左侧是宿主机端口,右侧是容器端口-d:后台运行容器
nginx:镜像名称,例如nginx
- docker start:启动已经存在的一个容器。
例如,使用下面的命令可以启动名为 mycontainer 的容器:
1 | docker start mycontainer |
- docker stop:停止正在运行的容器。
例如,使用下面的命令可以停止名为 mycontainer 的容器:
1 | docker stop mycontainer |
- docker rm:删除指定的容器。
例如,使用下面的命令可以删除名为 mycontainer 的容器:
1 | docker rm mycontainer |
- docker ps:列出所有正在运行的容器。
例如,使用下面的命令可以列出所有正在运行的容器:
1 | docker ps |
- docker exec:在正在运行的容器中执行命令。
例如,使用下面的命令可以在名为 mycontainer 的容器中运行一个 ls 命令:
1 | docker exec mycontainer bash |
进入Nginx容器,修改HTML文件内容,添加“传智教育欢迎您”
步骤一︰进入容器。
进入我们刚刚创建的nginx容器的命令为:
1 | docker exec -it mn bash |
命令解读:
- docker exec :进入容器内部,执行一个命令
- -it :给当前进入的容器创建一个标准输入、输出终端,允许我们与容器交互mn:要进入的容器的名称
- bash:进入容器后执行的命令,bash是一个linux终端交互命令
步骤二︰进入nginx的HTML所在目录
/usrlshare/nginx/ htmlcd /usr/share/nginx/html
步骤三:修改index.html的内容
1 | sed -i ' s#Welcome to nginx#传智教育欢迎您#g'index.html |
数据卷
数据卷基本操作
创建数据卷并查看数据卷在本机的位置:
创建数据卷
docker volume create html查看所有数据
docker volume ls查看数据卷详细信息卷
docker volume inspect html
数据卷挂载到容器
1 | docker run --name mn -v html:/root/html -p 8080:80 nginx |
docker run :就是创建并运行容器
–name mn:给容器起个名字叫mn
-v html:/root/htm : 把html数据卷挂载到容器内的/root/html这个目录中
-p 8080:80:把宿主机的8080端口映射到容器内的80端口
nginx:镜像名称
自定义镜像
了解镜像结构
镜像是分层结构,每一层称为一个Layer
- Baselmage层:包含基本的系统函数库、环境变量、文件系统(最底层)
- Entrypoint:入口,是镜像中应用启动的命令
- 其它:在Baselmage基础上添加依赖、安装程序、完成整个应用的安装和配置
自定义镜像
配置文件如下配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 指定基础镜像
FROM ubuntu:16.04
# 配置环境变量,JDK的安装目录
ENV JAVA_DIR=/usr/local
# 拷贝jdk和java项目的包
COPY ./jdk8.tar.gz $JAVA_DIR/
COPY ./docker-demo.jar /tmp/app.jar
# 安装JDK
RUN cd $JAVA_DIR \
&& tar -xf ./jdk8.tar.gz \
&& mv ./jdk1.8.0_144 ./java8
# 配置环境变量
ENV JAVA_HOME=$JAVA_DIR/java8
ENV PATH=$PATH:$JAVA_HOME/bin
# 暴露端口
EXPOSE 8090
# 入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar构建镜像
1 | docker build -t javaweb:1.0 . |
javaweb指的是镜像名称、1.0表示版本,后面的.表示构建镜像的步骤文件在本文件夹内
- 在镜像的基础上创建容器并运行
1 | docker run --name web -p 8090:8090 -d javaweb:1.0 |
鉴于每次部署java太麻烦,docker提供了一个名为java:8-alpine镜像,将一个java项目构建为镜像
实现思路如下:
- 新建一个空的目录,然后在目录中新建一个文件,命名为Dockerfile
- 拷贝课前资料提供的docker-demo.jar到这个目录中
- 编写Dockerfile文件:
- 基于java:8-alpine作为基础镜像b)将app.jar拷贝到镜像中
- 暴露端口
- 编写入口ENTRYPOINT使用docker build命令构建镜像
- 使用docker run创建容器并运行
DockerCompose
什么是DockerCompose
- Docker Compose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器!
- Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。
DockerCompose有什么作用
可以帮助我们快速部署分布式应用,无需一个个微服务去构建镜像和部署
案例:将之前写好的cloud-dome使用docker部署成微服务项目
使用步骤:
将需要的包放入其中包括gateway、mysql、order-service、user-service、nacos镜像
编辑配置文件docker-compose
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24version: "3.2"
services:
nacos:
image: nacos/nacos-server
environment:
MODE: standalone
ports:
- "8848:8848"
mysql:
image: mysql:5.7.25
environment:
MYSQL_ROOT_PASSWORD: 123
volumes:
- "$PWD/mysql/data:/var/lib/mysql"
- "$PWD/mysql/conf:/etc/mysql/conf.d/"
userservice:
build: ./user-service
orderservice:
build: ./order-service
gateway:
build: ./gateway
ports:
- "10010:10010"修改项目,将数据库、nacos地址都命名为docker-compose中的服务名
例如nacos:server-addr:local:80更改成nacos:server-addr:nacos:8848
mysql同理
使用maven打包工具,将项目中的每一个微服务都打包成app.jar
将打包好的app.jar拷贝到cloud-demo中的每一个对应的子目录中
将cloud-dome上传到虚拟机,利用dock-compose up -d来部署
同步通信和异步通信
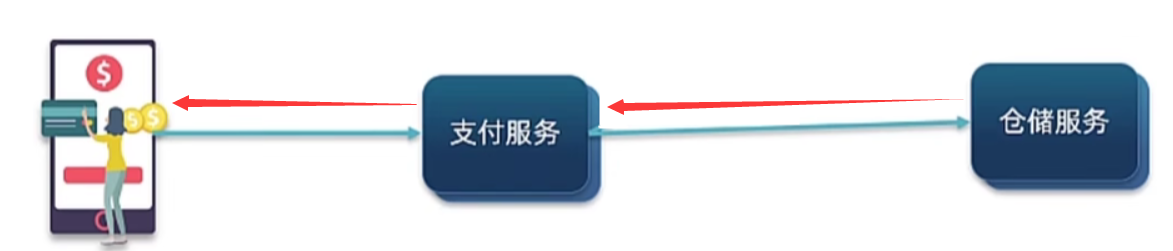
同步通信就像打电话一样,需要立即的响应和回应,而且在两个通信方之间只能进行单向或双向通信。如果有其他消息发送,就必须等待当前的通信完成后才能处理下一个请求。因此,同步通信会占用较多的资源,并且不太适合大量数据传输或高并发处理。
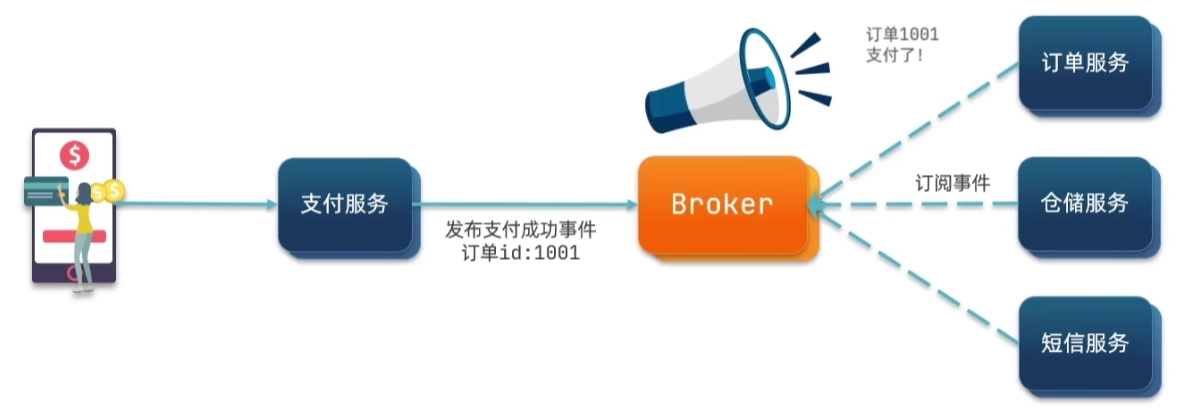
而异步通信更像是发短信一样,我把消息发送出去,就会立即显示发送成功。但是具体啥时候接收到响应就不管了。就像上面的例子用户支付完之后通知支付服务,支付服务会直接把支付成功发送给用户而不是等所有流程走完在发送。大大减少了传输时间。
RabbitMQ消息队列
单机部署和集群部署
单机部署:
在线拉取
1
docker pull rabbitmq:3-management
拉取后运行
1
docker load -i mq.tar
运行
1
2
3
4
5
6
7
8
9docker run \
-e RABBITMQ_DEFAULT_USER=root \
-e RABBITMQ_DEFAULT_PASS=510609 \
--name mq \
--hostname mq1 \
-p 15672:15672 \
-p 5672:5672 \
-d \
rabbitmq:3-management打开浏览器,地址栏搜索
1
http://192.168.136.131:15672/
输入自己设置的用户名和密码
RabbitMQ中的几个概念:.
channel:操作MQ的工具.
exchange:路由消息到队列中·
queue:缓存消息
virtual host:虚拟主机,是对queue、exchange等
资源的逻辑分组快速入门
基本消息队列的消息发送流程:
1.建立connection
2.创建channel
3.利用channel声明队列
4.利用channel向队列发送消息基本消息队列的消息接收流程:
1.建立connection
2.创建channel
3.利用channel声明队列
4.定义consumer的消费行为handleDelivery()5.利用channel将消费者与队列绑定
SpringAMQP
什么是AMQP
AMQP是用于在应用程序或之间传递业务消息的开放标准该协议与语言和平台无关,更符合微服务中独立性的要求
Spring AMQP是基于AMQP协议定义的一套API规范,提供了模板来发送和接收消息。包含两部分,其中spring-amqp是基础抽象,spring-rabbit是底层的默认实现。
消息的发送和接收(入门)

消息发送:
配置rabbitAMOP
1
2
3
4
5
6
7spring:
rabbitmq:
host: 192.168.136.131
port: 5672
username: root
password: 510609
virtual-host: /新建测试类
编写发送
1
2
3
4
5
6
7
8
9
10
11
12
13
public class SpringAmqpTest {
private RabbitTemplate rabbitTemplate;
public void testSendMessage2SimpleQueue(){
String queueName="simple.queue";
String message="hello,spring amqp!";
rabbitTemplate.convertAndSend(queueName,message);
}
}
消息接收:
配置rabbitAMOP
1
2
3
4
5
6
7spring:
rabbitmq:
host: 192.168.136.131
port: 5672
username: root
password: 510609
virtual-host: /新建类
类中编写
1
2
3
4
5
6
7@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String msg){
System.out.println("消费者接收到的simple.queue:【"+msg+"】");
}
}
控制台返回:消费者接收到的simple.queue:【hello,spring amqp!】
work Queue工作队列
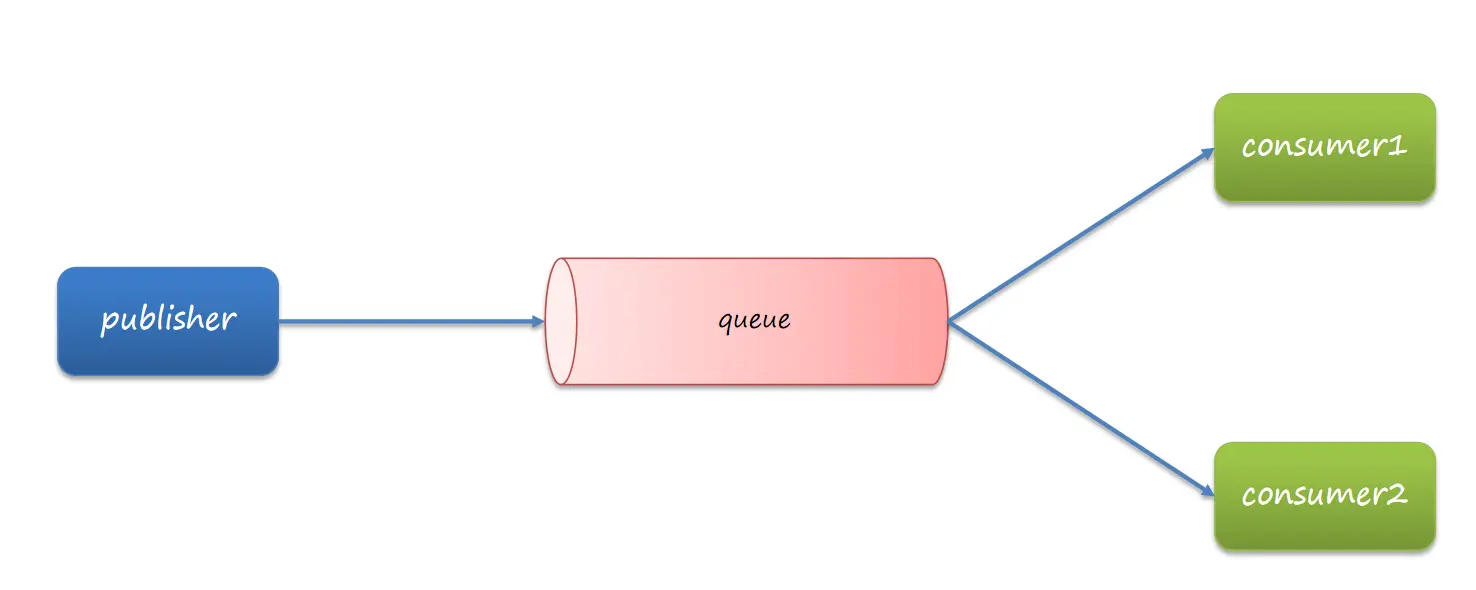
Work Queue,工作队列,可以提高消息处理速度,避免队列消息堆积
publisher在发送消息之后会将消息存放在queue中等待connection处理
默认轮询模式下,Work Queue会将生产者生产的消息一次性平均分配给consumer1和consumer2,当分配完消息后,它的自动确认机制会一次性全部确认。而不在乎自己能不能处理,届时就会出现消息堆积问题
而最好的方法就是在配置文件中添加消费策略
例子:
测试:发送消息50次
1
2
3
4
5
6
7
8
9
public void testSendMessage2WorkQueue() throws InterruptedException {
String queueName="simple.queue";
String message="hello,message_ _";
for (int i = 1; i <=50 ; i++) {
rabbitTemplate.convertAndSend(queueName,message+i);
Thread.sleep(20);
}
}添加两个消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class SpringRabbitListener {
public void listenSimpleQueue(String msg) throws InterruptedException {
System.out.println("消费者1 接收到的simple.queue:【"+msg+"】"+ LocalTime.now());
Thread.sleep(20);
}
public void listenSimpleQueue2(String msg) throws InterruptedException {
System.out.println("消费者2.....接收到的simple.queue:【"+msg+"】"+LocalTime.now());
Thread.sleep(200);
}
}解决消费策略问题
1
2
3
4
5
6
7
8
9
10
11spring:
rabbitmq:
host: 192.168.136.131
port: 5672
username: root
password: 510609
virtual-host: /
#表示每次只处理一条消息
listener:
simple:
prefetch: 1
发布和订阅
发布订阅模式与之前案例的区别就是允许将同一消息发送给多个消费者。实现方式是加入了exchange(交换机)
常见exchange类型包括:
- Fanout:广播
- Direct:路由
- Topic:话题
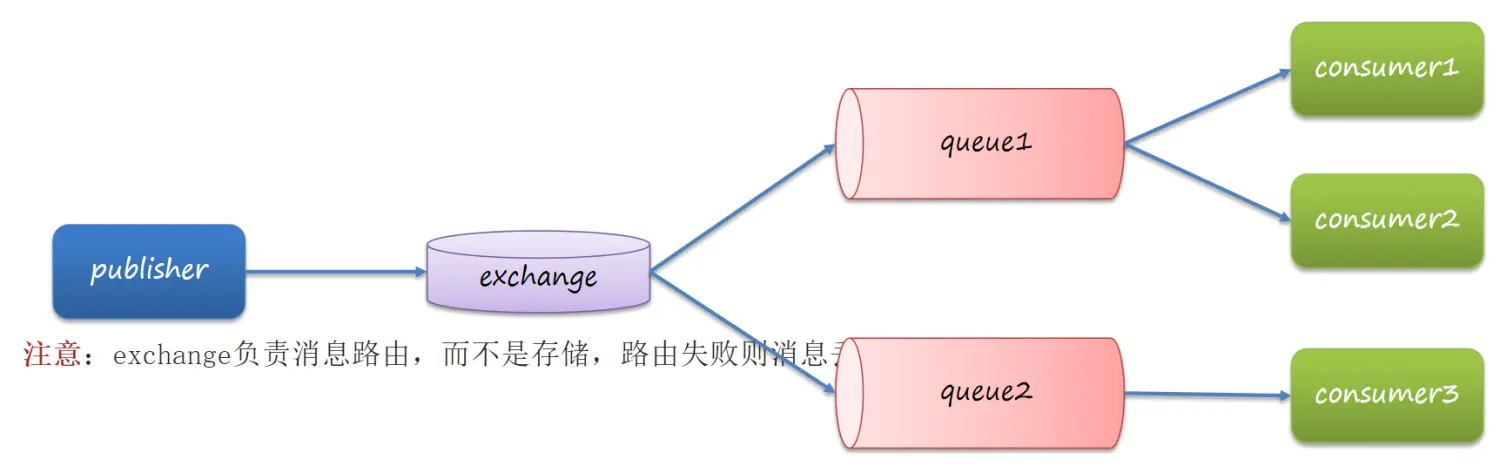
注意:exchange负责消息路由,而不是存储,路由失败则消息丢失
FanoutExchange
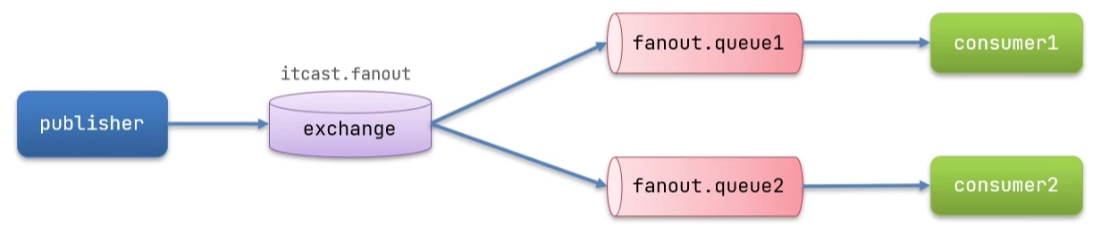
所谓FanoutExchange就是把消息传递给交换机,而交换机会将消息分别发送给消息队列1和消息队列2
实现思路如下:
在consumer服务中,利用代码声明队列、交换机,并将两者绑定
在consumer服务中,编写两个消费者方法,分别监听fanout.queue1和fanout.queue2
在publisher中编写测试方法,向itcast.fanout发送消息
编写FanoutConfig:
1 |
|
- 编写两个消费者方法,分别监听fanout.queue1和fanout.queue2
1 |
|
- 在publisher中编写测试方法,向itcast.fanout交换机发送消息
1 |
|
得到输出:
消费者接收到fanout.queue2的消息是:【hello,every one!】
消费者接收到fanout.queue1的消息是:【hello,every one!】
DirectExchange
DirectExchange交换机是指提供者在发送消息时携带着一个key,就像暗号一样。而队列中会定义一个key,当发送的消息经过交换机时,交换机会核对到底是哪个消息队列和key匹配。如果几个消息队列中都存在这个key就都可以得到消息。
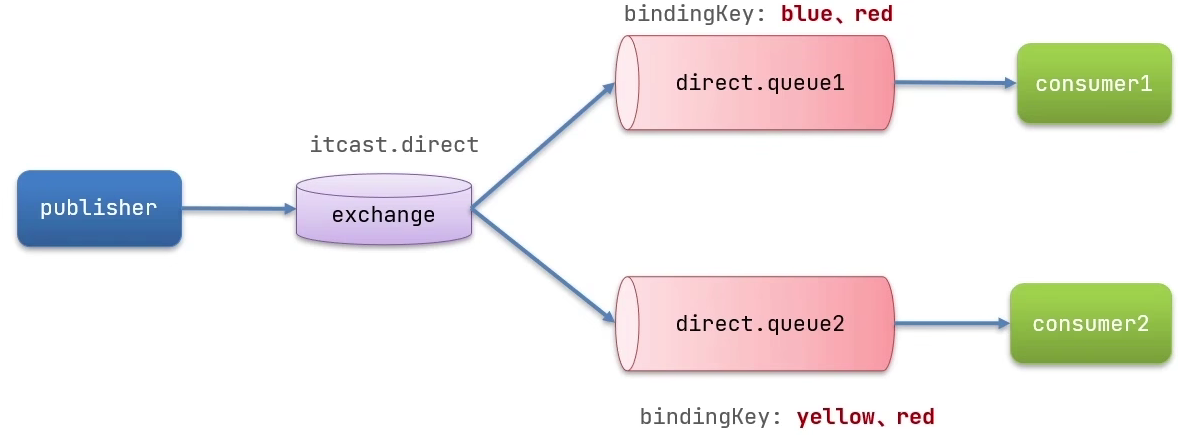
实现思路如下:
在consumer服务中,编写两个消费者方法,利用@RabbitListener声明Exchange、Queue、RoutingKey
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class SpringRabbitListener {
public void listenDirectQueue1(String msg){
System.out.println("消费者接收到direct.queue1的消息:【" + msg + "】");
}
public void listenDirectQueue2(String msg){
System.out.println("消费者接收到direct.queue2的消息:【" + msg + "】");
}
}
在publisher中编写测试方法,向itcast. direct发送消息
1
2
3
4
5
6
7
8
9
public void testSendDirectExchange( ){
//交换机名称
String exchangeName = "itcast.direct";
//消息
String message = "hello, blue ! ";
//发送消息
rabbitTemplate.convertAndSend(exchangeName, "blue", message);
}
TopicExchange
TopicExchange与DirectExchange类似,区别在于routingKey必须是多个单词的列表,并且以.分割。
Queue与Exchange指定BindingKey时可以使用通配符:
- #:代指0个或多个单词
- *:代指一个单词
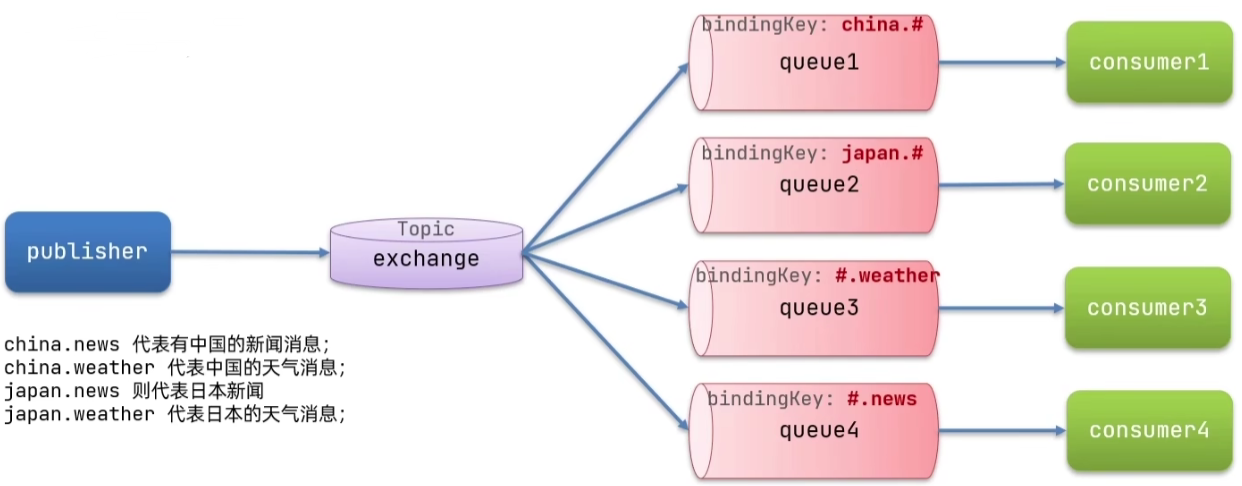
实现思路如下:
在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2并利用@RabbitListener声明Exchange、Queue、RoutingKey
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class SpringRabbitListener {
public void listenTopicqueue1(String msg) {
System.out.println("消费者接收到topic.queue1的消息:【" + msg + "]");
}
public void listenTopicqueue2(String msg) {
System.out.println("消费者接收到topic.queue1的消息:【" + msg + "]");
}
}在publisher中编写测试方法,向itcast.topic发送消息
1
2
3
4
5
6
7
8
9
public void testSendTopicExchange() {
//交换机名称
String exchangeName = "itcast.topic";
//消息
String message ="传智教育在深交所上市了!是教育行业IPO第一股!";
//发送消息
rabbitTemplate.convertAndSend(exchangeName,"china.news",message);
}
消息转换器
Spring对消息对象的处理是由org.springframework.amqp.support.converter.MessageConverter来处理的。而默认实现是SimpleMessageConverter,基于JDK的ObjectOutputStream完成序列化。
如果要修改只需要定义一个MessageConverter 类型的Bean即可。推荐用JSON方式序列化,步骤如下:
发送消息:
- 我们在父工程引入依赖
1 | <dependency> |
- 我们在publisher启动类中声明MessageConverter:
1 |
|
- 接收消息:
- 我们在consumer启动类中定义MessageConverter:
1 |
|
- 然后定义一个消费者,监听object.queue队列并消费消息:
1 |
|

